
2017 年 10 月的杭州云棲大會上,阿里巴巴正式宣布成立達摩院���,未來三年將投入將超過 1000 億人民幣用于基礎(chǔ)科學(xué)和顛覆式技術(shù)創(chuàng)新研究��。達摩院官網(wǎng)正式上線后�,我們看到達摩院重點布局機器智能��、數(shù)據(jù)計算�、機器人、金融科技以及X實驗室五大領(lǐng)域�,相應(yīng)設(shè)置有 14 個實驗室���,共有近 70 名海內(nèi)外專家坐鎮(zhèn)�����。
AI 技術(shù)是達摩院目前重金押注的技術(shù)領(lǐng)域之一�,即將成立兩年���,人們可能都比較好奇達摩院在AI上到底布局了哪些技術(shù)領(lǐng)域�����?又在哪些技術(shù)方向上取得了突破�����?本文將一一盤點達摩院在AI技術(shù)上的重大進展��。
阿里AI 的技術(shù)發(fā)展及平臺建設(shè)
阿里擁有全面的 AI 技術(shù)布局���,涵蓋語音智能����、語言技術(shù)��、機器視覺�����、決策智能等方向�,建成了完善的機器智能算法體系, 不僅囊括語音�、視覺、自然語言理解�、無人駕駛等技術(shù)應(yīng)用領(lǐng)域,還不斷深化AI基礎(chǔ)設(shè)施建設(shè)����,重金投入研發(fā)AI芯片���、超大規(guī)模機器學(xué)習(xí)平臺,并建成了單日數(shù)據(jù)處理量突破 600PB 的超大計算平臺�����。
下面�,我們主要圍繞語音智能、語言技術(shù)��、機器視覺三大技術(shù)領(lǐng)域與平臺化建設(shè)的最新發(fā)展與成績���,一覽阿里 AI 技術(shù)這兩年的進展��。
(一)語音智能
2018年6月,阿里達摩院開源了自主開發(fā)的新一代語音識別模型(DFSMN)�����,在世界最大的免費語音識別數(shù)據(jù)庫 LibriSpeech 上進行公開測試��。對比目前業(yè)界使用最為廣泛的 LSTM 模型�����,DFSMN 語音識別模型訓(xùn)練速度更快、識別準確率更高�����?�;?DFSMN 模型��,阿里 AI 又研發(fā)了 DFSMN-CTC 模型�,語音錯誤率大幅下降,解碼效率提升6倍���。
此外��,阿里巴巴機器智能技術(shù)實驗室正在研發(fā)高工業(yè)噪聲環(huán)境下的語音識別及傳輸技術(shù)����。以后���,眾多車間工人將告別“通訊靠吼”的境況�,簡單的交流言語會轉(zhuǎn)換成文字����。目前���,在85分貝工業(yè)噪聲下,可以實現(xiàn)將一米處正常音量語音轉(zhuǎn)換為文字���,準確率達94.6%�����,能夠解決大部分工廠里的噪聲聾問題��。這項工作仍在繼續(xù)���,未來團隊希望可以實現(xiàn) 95 分貝工業(yè)噪聲下進行語音識別。

阿里巴巴工程師正在調(diào)試AI語音識別系統(tǒng)
目前�����,阿里語音 AI 每日調(diào)用量已達1.8 億次���。
2019 年 7 月,阿里開源人機對話模型 ESIM����。ESIM 是一個解決多輪對話回復(fù)問題的原創(chuàng)模型�,通過給對話機器人裝上實時搜索并理解人類真實意圖的“雷達”系統(tǒng)��,實現(xiàn)對對話歷史的實時檢索��,自動去除多余信息的干擾���,給出人類期待的回復(fù)�����。
例如當(dāng)人們線上購物時���,提出要一件M號的黑色裙子,智能機器人通過對庫存情況的實時檢索����,發(fā)現(xiàn)并答復(fù)用戶沒有黑色M號的裙子。用戶接著問�����,“那有白色的嗎����?”此時傳統(tǒng)模型訓(xùn)練出的AI客服很難判斷用戶是要問“這件裙子是否有白色款”還是“有沒有白色的M號裙子”��,無法給出準確回復(fù)�。
阿里 AI 通過對用戶對話上下文的檢索��,明確用戶的核心在于尺寸而非顏色����,很快給出有沒有白色M號裙子的準確回復(fù)。
這項技術(shù)未來將會被應(yīng)用到人機交互的多個場景:智能語音點餐機能夠更準確地理解人們的真實意圖���,提高點單成功率����;導(dǎo)航軟件能更容易聽懂人們的語音請求�,少走冤枉路;家里的智能音箱能夠更快做出反應(yīng)�����,節(jié)省等待時間����。
阿里達摩院機器智能實驗室自主研發(fā)的基于翻譯的合成技術(shù) Knowledge-Aware Neural TTS(KAN-TTS)深度融合了目前主流的端到端 TTS 技術(shù)和傳統(tǒng) TTS 技術(shù),同時系統(tǒng)構(gòu)建了基于不同領(lǐng)域的深層知識���。并針對 CPU 部署的框架設(shè)計進行優(yōu)化�����,提供高效��、便捷的部署能力���,另外還改進了 20 多項關(guān)鍵算法,從多個方面改進了語音合成�����。
傳統(tǒng)語音合成定制需要10小時以上的數(shù)據(jù)錄制和標注��,對錄音人和錄音環(huán)境要求很高��。從啟動定制到最終交付��,項目周期長成本高��。阿里利用 Multi-Speaker Model 與 Speaker-aware Advanced Transfer Learning 相結(jié)合的方法��,將語音合成定制成本降低 10 倍以上,周期壓縮 3 倍以上����。也就是說,用 1 小時有效錄音數(shù)據(jù)和不到兩個月制作周期�����,就能完成一次標準 TTS 定制���。
這也意味著�����,普通用戶定制“AI聲音”的門檻更低�����。只需手機錄音十分鐘����,就能獲得與錄制聲音高度相似的合成語音�����。阿里 AI 做到這一點,主要基于自動數(shù)據(jù)檢查����、自動標注方法和對海量用戶場景的利用����。阿里已經(jīng)對外提供開箱即用的 TTS 解決方案,共有通用��、客服�、童聲、英文和方言 5 個場景的34 種聲音供選擇�。基于新一代技術(shù)���,阿里還提高了設(shè)備端離線 TTS 的效果�����。這在超低資源設(shè)備端的 TTS 服務(wù)中非常有用��,比如當(dāng)人們駕車行駛于信號微弱區(qū)域時避免語音導(dǎo)航“掉線”�。
除了在語音識別、語音交互與語音合成等領(lǐng)域的進展��,在聲紋識別領(lǐng)域��,阿里達摩院研發(fā)了聲紋無監(jiān)督聚類技術(shù)���,推出分布式語音交互模組�,用于阿里云 IoT 聯(lián)合阿里達摩院發(fā)布的分布式語音交互解決方案中�,方案除了語音交互模組外���,還包括語音自學(xué)習(xí)平臺���、對話平臺以及阿里云 IoT 智能人居平臺,打通了上下游平臺串聯(lián)���、端云一體能力���,縮短智能人居環(huán)境開發(fā)周期,同時還具備強擴展能力���。
(二)自然語言處理
2017 年的 WMT 競賽����,大多數(shù)系統(tǒng)是基于 RNN 和 LSTM,包括最終獲得冠軍的系統(tǒng)也是基于此�。僅僅過了一年時間,各大機構(gòu)都爭先使用 Transformer����。達摩院機器智能技術(shù)實驗室資深算法專家陳博興帶領(lǐng)的達摩院機器翻譯團隊,在此次比賽中���,基于 Transformer 結(jié)構(gòu), Self-Attention�、Multi-head Attention 等技術(shù),進行了網(wǎng)絡(luò)結(jié)構(gòu)的改進����,充分利用詞語位置信息,提出高度并行化��、能捕捉層次化信息的神經(jīng)網(wǎng)絡(luò)���,全面提升了機器翻譯的性能���。
去年,AI科技大本營也邀請了阿里巴巴機器智能技術(shù)實驗室阿里巴巴翻譯平臺翻譯模型組負責(zé)人于恒做了公開課分享:《Transformer 新型神經(jīng)網(wǎng)絡(luò)在機器翻譯中的應(yīng)用 | 公開課筆記》
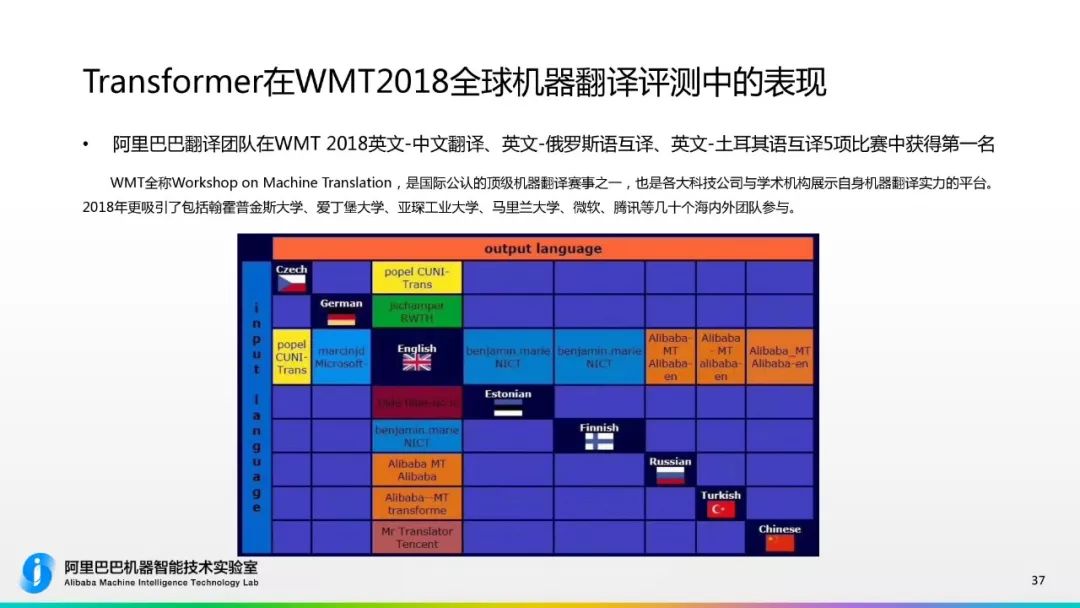
目前,達摩院機器翻譯技術(shù)團隊已實現(xiàn)了 48 個語言翻譯方向���,支持俄�����、西����、法���、阿��、土��,泰��、印尼��、越南等多種語言翻譯�;其中電商覆蓋了大部分語向和場景��,超越谷歌和亞馬遜����,日調(diào)用量達到 17.9 億次�����。阿里的機器翻譯技術(shù)除了應(yīng)用于電商全鏈路服務(wù)之外�,還廣泛應(yīng)用于菜鳥物流通關(guān)�����、阿里云國際社區(qū)�、飛豬旅行翻譯助手、釘釘社交口語翻譯等一系列產(chǎn)品�。
傳統(tǒng) AI 閱讀需要某一領(lǐng)域的專業(yè)人士準備好問答數(shù)據(jù)�����,AI 回答也僅限于該領(lǐng)域��,例如金融領(lǐng)域的人工智能無法回答物流領(lǐng)域的問題��。阿里研究團隊提出的“基于分層融合注意力機制”的深度神經(jīng)網(wǎng)絡(luò)模型能夠模擬人類在做閱讀理解問題時的一些行為�,包括結(jié)合篇章內(nèi)容審題,帶著問題反復(fù)閱讀文章��,避免閱讀中遺忘而進行相關(guān)標注等。模型可以在捕捉問題和文章中特定區(qū)域關(guān)聯(lián)的同時�,借助分層策略,逐步集中注意力���,使答案邊界清晰�����;另一方面��,為避免過于關(guān)注細節(jié)�,采用融合方式將全局信息加入注意力機制���,進行適度糾正�����,確保關(guān)注點正確����。
比如���,4300 萬字的《大英百科全書》�,阿里 AI 可以在毫秒內(nèi)閱讀完,并根據(jù)自己的理解快速回答涉及書中不同領(lǐng)域的不同問題�。例如亞洲有多少個國家?美國第五任總統(tǒng)是誰�?恐龍是什么時候消失的?機器人可以分別迅速給出答案��,無懼“連環(huán)追擊”���。
阿里還提出了基于“融合結(jié)構(gòu)化信息 BERT 模型”的“深度級聯(lián)機器閱讀模型”�����,可以模仿人類閱讀理解的過程����,先對文檔進行快速瀏覽�,判斷�����,然后針對相應(yīng)段落進行精讀����,并根據(jù)“自己的理解”回答問題����。
常識推理可以說是難度最高的 NLP 任務(wù)之一��,深度學(xué)習(xí)領(lǐng)軍人物之一����、圖靈獎獲得者 Yann LeCun 曾有斷言:最聰明的AI在常識方面也不如貓。
阿里巴巴達摩院語音實驗室還提出了 AMS 方法����,顯著提升 BERT 模型的常識推理能力。AMS 方法使用與 BERT 相同的模型���,僅預(yù)訓(xùn)練 BERT��,在不提升模型計算量的情況下�����,將 CommonsenseQA 數(shù)據(jù)集上的準確率提升了 5.5%�����,達到 62.2%�����。
2019 年 4 月 1 日愚人節(jié)之際�����,阿里巴巴發(fā)布了這項旨在粉碎網(wǎng)絡(luò)謠言和假新聞的AI技術(shù)——“AI謠言粉碎機”��。其算法模型由阿里巴巴達摩院機器智能實驗室研發(fā)�,依靠深度學(xué)習(xí)和神經(jīng)網(wǎng)絡(luò)技術(shù),通過對信息的多維度和多角度分析�����,團隊設(shè)計了一整套包含發(fā)布信息��、社交畫像��、回復(fù)者立場��、回復(fù)信息����、傳播路徑在內(nèi)的綜合判定系統(tǒng)���,首次把謠言識別和社交用戶觀點識別打通����,并做交叉分析,目前在特定場景中的準確率已經(jīng)達到 81%����,最快能夠在 1 秒內(nèi)判定新聞的真實性。
(三)機器視覺
2017 年 7 月�����,國際權(quán)威肺結(jié)節(jié)檢測大賽 LUNA16 要求選手對 888 份肺部 CT 樣本進行分析�,尋找其中的肺結(jié)節(jié)。樣本共包含 1186 個肺結(jié)節(jié)��,75% 以上為小于 10mm 的小結(jié)節(jié)����。最終,阿里云 ET 在 7 個不同誤報率下發(fā)現(xiàn)的肺結(jié)節(jié)平均召回率達到 89.7%�����。(召回率指在樣本數(shù)據(jù)中成功發(fā)現(xiàn)的結(jié)節(jié)占比,下圖顯示了 ET 在不同誤報次數(shù)下的召回率情況��。)
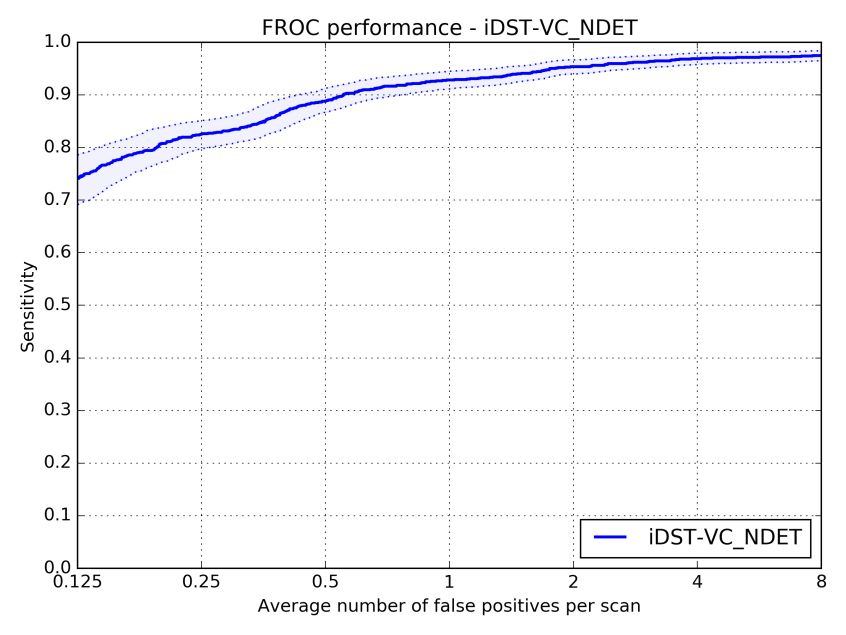
(FROC曲線)
其背后的技術(shù)由阿里巴巴 iDST視覺計算團隊完成�,負責(zé)人華先勝介紹,與常用的兩階段檢測方法不同��,他們創(chuàng)新性地使用了單階段方法�����,全程無須人工干預(yù)���。機器全自動讀取病人的 CT 序列���,直接輸出檢測到的肺結(jié)節(jié)。在模型結(jié)構(gòu)設(shè)計上����,ET 針對 CT 切片的特性,采用多通道�����、異構(gòu)三維卷積融合算法����、有效地利用多異構(gòu)模型的互補性來處理和檢測在不同形態(tài)上的肺結(jié)節(jié) CT 序列,提高了對不同尺度肺結(jié)節(jié)的敏感性�;同時使用了帶有反卷積結(jié)構(gòu)的網(wǎng)絡(luò)和多任務(wù)學(xué)習(xí)的訓(xùn)練策略,提高了檢測的準確度�����。比賽中�,團隊克服了一系列挑戰(zhàn):如結(jié)節(jié)模態(tài)復(fù)雜問題,早期的結(jié)節(jié)?����。ㄐ∮?0mm)����,傳統(tǒng)的機器學(xué)習(xí)和用于自然圖像的深度學(xué)習(xí)網(wǎng)絡(luò)通常難以湊效。
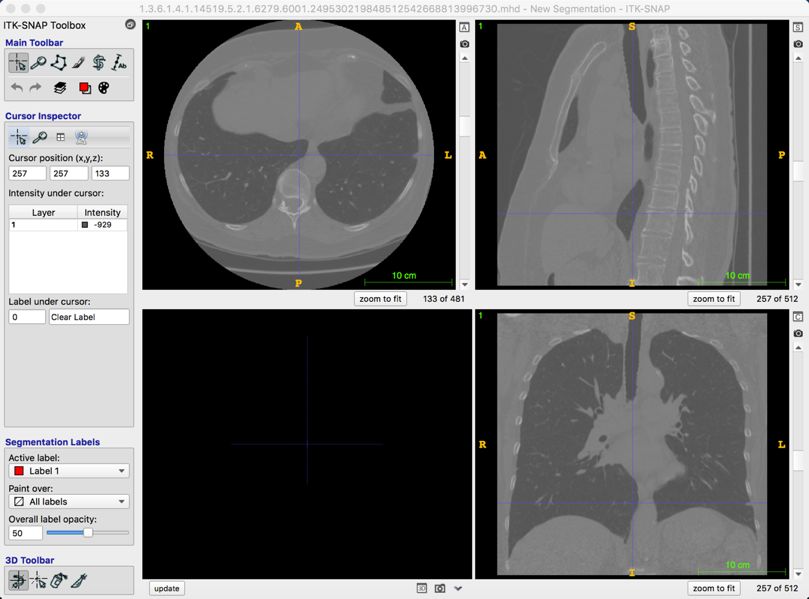
肝結(jié)節(jié)的準確測量可以輔助醫(yī)生做出決策和治療方案�����。但肝結(jié)節(jié)形態(tài)多樣�,即使是同一個病人,結(jié)節(jié)的大小�、形狀都不一樣��,從而導(dǎo)致結(jié)節(jié)間灰度分布差異大���、或與周圍組織灰度相似,甚至沒有清晰的邊界�����。
阿里則通過對 CT 圖像層間信息和層內(nèi)信息融合的網(wǎng)絡(luò)結(jié)構(gòu)分析�����,解決肝結(jié)節(jié)類別多樣性的問題���。采用基于原子卷積的空間金字塔池化(Atrous Spatial Pyramid Pooling)����、亞像素卷積(Sub Pixel Convolution)及多特征融合等技術(shù)���。華先勝表示�����,目前團隊研究范圍已經(jīng)覆蓋肺��、肝���、骨�、心臟����、腦等部位的疾病��,涉及影像分析�、自然語言處理、設(shè)備信號處理等相關(guān)技術(shù)�����,部分技術(shù)已經(jīng)落地到實際的醫(yī)療診斷中�����。
2019年6月�����,在被譽為人工智能世界杯的 WebVision 競賽要求參賽的 AI 模型將 1,600 萬張圖片精準分類到 5,000 個類目中�。相比于經(jīng)過人工標注完畢的 ImageNet 數(shù)據(jù)集�����,WebVision 所用數(shù)據(jù)集直接從互聯(lián)網(wǎng)爬取�,沒有經(jīng)過人工標注�����,含有較多噪音�����,且數(shù)據(jù)類別的數(shù)量組成極大不平衡�����,AI 的識別難度更高���。
阿里 AI 引入了構(gòu)建類別語義標簽關(guān)系的模型�����,并采用輔助信息模型進行圖像去噪的深度學(xué)習(xí)技術(shù)����,以及阿里自研的可以支持數(shù)十億圖片分類訓(xùn)練的超大平臺。最終���,阿里 AI 以 82.54% 的識別準確率��,擊敗全世界 150 多支參賽隊獲得冠軍�,目前該技術(shù)可以識別超過 100 萬種物理實體���。
2019 年 7 月,在 CVPR 2019 舉辦的 LPIRC(低功耗圖像識別挑戰(zhàn)賽)中�,阿里 AI 獲得在線圖像分類任務(wù)第一名,以 23ms 的單張圖片分類速度���,在 10 分鐘內(nèi)分類 20,000 張圖像���。在挑戰(zhàn)賽使用的訓(xùn)練數(shù)據(jù)集上,實現(xiàn)了 67.4% 的分類精度����,比官方提供的基準線高3.5%。
視覺對話
視覺對話是近年來快速崛起的 AI 研究方向�,目的在于教會機器用自然語言與人類討論視覺內(nèi)容。如果說視覺識別技術(shù)���,讓機器具備了視覺能力�����;那么視覺對話技術(shù)�,則使機器擁有了對真實視覺世界的理解與推斷能力,意味著 AI 的認知能力將邁上新的臺階�。
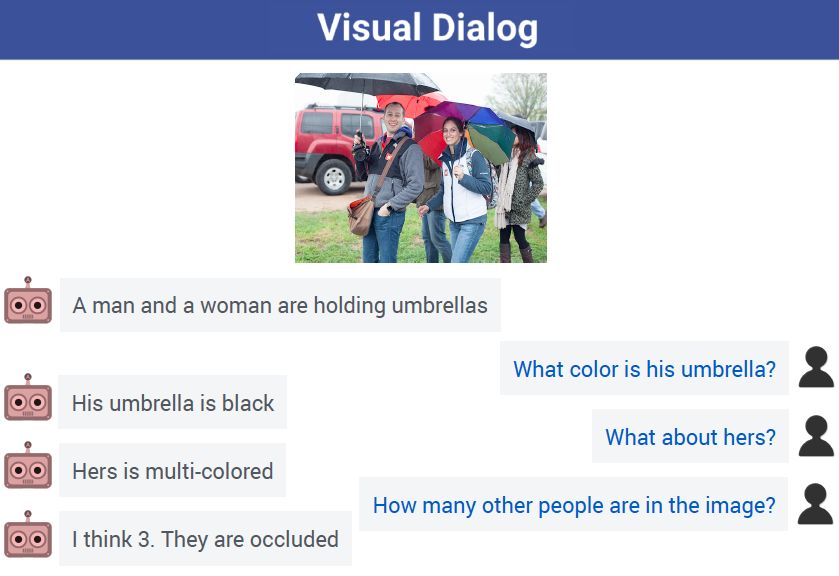
(視覺對話中,AI可以從容應(yīng)對人類提問���,左為AI��,右為人類)
傳統(tǒng)的視覺 AI 主要針對目標的檢測和識別���,例如識別出圖片是否是一只貓,但對復(fù)雜場景中目標之間的邏輯關(guān)系理解�����、推理能力較弱�,無法回答“這只貓旁邊的男生穿了什么顏色的衣服”等復(fù)雜問題,也難以將圖片信息轉(zhuǎn)化為人類理解的語言輸出���。
阿里 AI 提出了“遞歸探索對話模型”����,綜合集成了圖像識別、關(guān)系推理與自然語言理解三大能力���,通過高效利用標注信息學(xué)習(xí)出模仿人類認知復(fù)雜場景的思維方式�,能夠有效識別圖片里的實體以及它們之間的關(guān)系�,推理出圖片所描述的事件內(nèi)容,并通過對上下文進行有效建模�,理解人類提出的問題及真實意圖,給出自然準確的回復(fù)�����。
未來�,視覺對話技術(shù)將被應(yīng)用在人機交互的諸多場景中���。地震后在廢墟中尋找幸存者的救援機器人�����,能更加及時����、高效地綜合指揮指令和場景信息作出行動;視障人士可以通過提問AI理解網(wǎng)絡(luò)照片中的內(nèi)容����,了解自身所處的周圍環(huán)境;無人駕駛車輛對影響因子的意圖理解會更為準確����,乘客的乘坐體驗更好。
(四)阿里 AI 的基礎(chǔ)平臺建設(shè)
在 AI 應(yīng)用技術(shù)上的不斷探索之外��,阿里不斷深化 AI 基礎(chǔ)設(shè)施建設(shè)�。機器學(xué)習(xí)平臺為人工智能發(fā)展提供深度學(xué)習(xí)數(shù)據(jù)處理和模型訓(xùn)練的一站式服務(wù),阿里研發(fā)了大規(guī)模分布式機器學(xué)習(xí)平臺 PAI���,讓企業(yè)和開發(fā)者擁有便捷的人工智能開發(fā)能力���,大幅降低使用人工智能的成本。該平臺是國內(nèi)首個集數(shù)據(jù)處理�����、建模�、離線預(yù)測、在線預(yù)測為一體的機器學(xué)習(xí)平臺,提供 100 余種算法組件�,支持千億特征、萬億模型和萬億樣本乃至 PB 級的數(shù)據(jù)訓(xùn)練����,為傳統(tǒng)機器學(xué)習(xí)提供上百種算法和大規(guī)模分布式計算的服務(wù)。
2018 年杭州云棲大會上���,針對廣告���、搜索、推薦等典型數(shù)據(jù)處理場景�����,發(fā)布自研新一代工業(yè)級分布式深度學(xué)習(xí)框架——XDL��,關(guān)注的核心是這些場景下高維稀疏數(shù)據(jù)的性能����。
大規(guī)模算力是支撐的機器智能高效應(yīng)用的基礎(chǔ)����。阿里擁有豐富的異構(gòu)計算平臺和自研的大規(guī)模分布式計算引擎(Maxcompute),包括超大規(guī)模批量計算、超高并發(fā)實時計算����、復(fù)雜圖數(shù)據(jù)推理計算三類,綜合性能上領(lǐng)先現(xiàn)有開源引擎 30%���,整體成本降低 20%��。在 2018 年雙十一��,MaxCompute 單日數(shù)據(jù)處理量突破 600 PB���。
基于淘寶和達摩院的研究成果,阿里 2017 年開始組建 MNN 團隊����。2019 年 5 月,阿里開源了首個移動 AI 項目——輕量級的深度神經(jīng)網(wǎng)絡(luò)推理引擎MNN(Mobile Neural Network)��,具有輕量�����、通用��、高性能、易用性特征�。MNN 提供模型轉(zhuǎn)換和計算推理兩大功能,模型轉(zhuǎn)換功能幫助開發(fā)者兼容不同的訓(xùn)練框架�,如 TensorFlow(Lite)、ONNX 等�;計算推理部分應(yīng)用了多種優(yōu)化方法,高效推理�����。MNN 可用在智能手機�����、IoT 設(shè)備等端側(cè)加載深度神經(jīng)網(wǎng)絡(luò)模型�,可應(yīng)用于阿里手機淘寶、手機天貓�����、優(yōu)酷等 20 多個應(yīng)用�,覆蓋直播、短視頻���、搜索推薦����、商品圖像搜索�、互動營銷、權(quán)益發(fā)放�����、安全風(fēng)控等場景��。
達摩院:阿里 AI 發(fā)展的“總樞紐”
雖然阿里在人工智能賽道的起步不算最早����,不過等到AI風(fēng)口在2015年前后起勢,阿里也儲備了相當(dāng)分量的AI人才���。兩年前�����,阿里組建達摩院���,全面升級人工智能的技術(shù)、商業(yè)布局����。某種程度上����,達摩院的組建是阿里人工智能組織力量的重大升級�,奠定了這兩年阿里AI技術(shù)飛速發(fā)展的基礎(chǔ)。
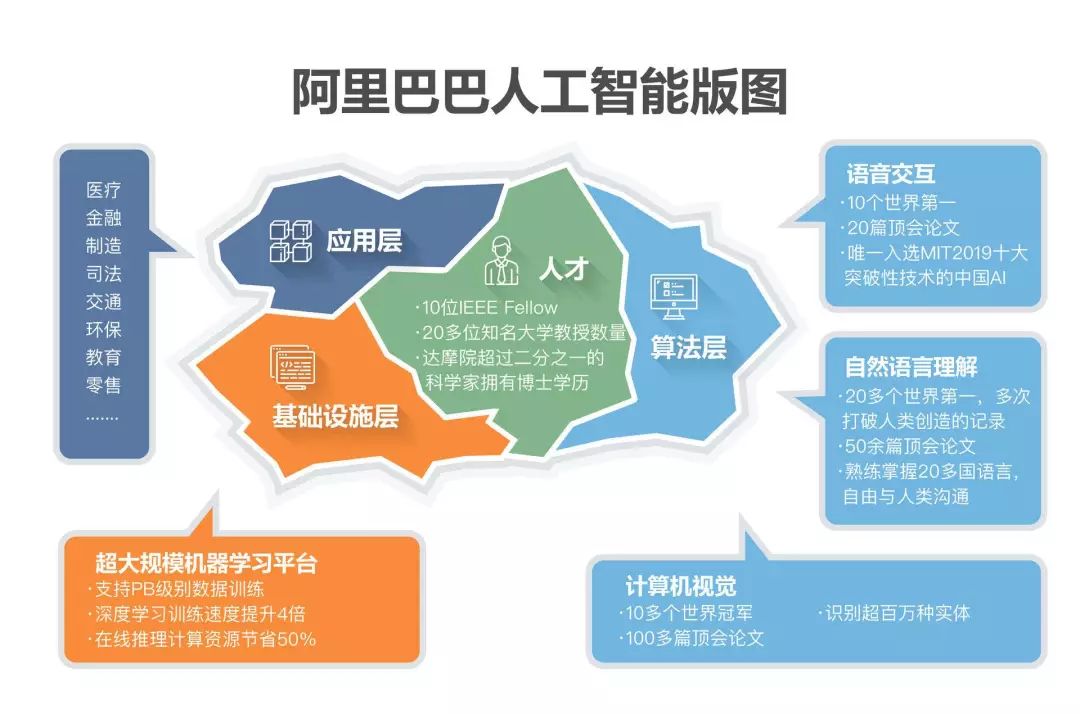
當(dāng)然�,技術(shù)能否帶來經(jīng)濟社會生活的改變,能否帶來商業(yè)化場景大規(guī)模落地��,才是技術(shù)價值的最終體現(xiàn)�����。在人工智能領(lǐng)域�,技術(shù)應(yīng)用的商業(yè)化是衡量價值的唯一標準,而阿里產(chǎn)業(yè)AI目前已遍及醫(yī)療����、金融、制造���、司法�����、交通����、環(huán)保��、教育����、零售等領(lǐng)域。
領(lǐng)先的算法技術(shù)�����、AI 應(yīng)用的系統(tǒng)集成能力��、AI 產(chǎn)業(yè)生態(tài)構(gòu)建能力�、海量用戶場景、開源技術(shù)生態(tài)�、大規(guī)模研發(fā)投入和頂級人才團隊以及自身的AI商業(yè)化模式是阿里 AI 取得現(xiàn)有成績的關(guān)鍵組成部分,而阿里達摩院無疑是將這些因子串聯(lián)起來的“總樞紐”���。